
“One afternoon I watched an agent spin up AWS tasks with a single prompt… and realized we’d given it the keys to the kingdom.”
TL;DR: The Runtime Shape
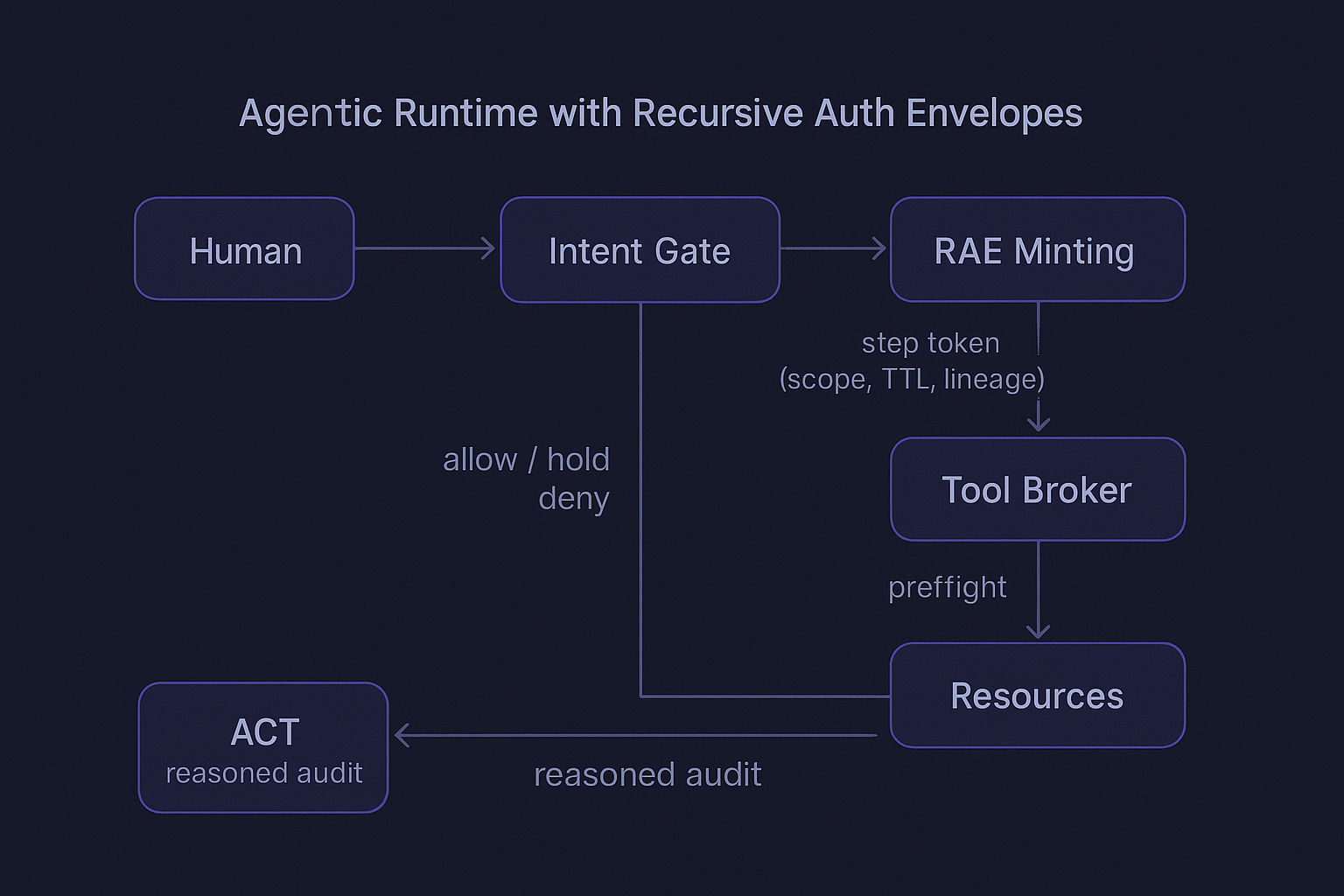
TL;DR: Human intent → policy → per-step RAE → brokered execution → ACT audit.
- AIB: Agent executes only under human-scoped, step-scoped delegation
- RAE: Per-step ephemeral envelope (scope, TTL, parent lineage)
- Broker: Enforces envelope before any side effect; no direct tool calls
- ACT: Redacted, hash-linked “why” graph for real audit
- Effects: Tools typed as read/mutate/destroy for policy by effect
- Egress: Semantic outbound controls over sensitive vector fingerprints
Stop Calling Interpreters “Non‑Human Identities”
If you treat an LLM-based agent as an “API” or a “service account,” you’ll give it exactly the wrong shape of power.
- An API identity models a deterministic surface.
- A service account models a machine principal with static capabilities.
- An LLM agent is neither. It’s a recursive interpreter that synthesizes behavior, chains tools, rewrites its own plan, and mutates context mid-flight.
“Non-human identity” is the wrong abstraction for something that (a) composes actions that you didn’t enumerate and (b) routes through identities you didn’t bind. The difference matters, because your blast radius is no longer the permission set—it’s the interpreter’s reachable state space.
You can’t ring‑fence that with keyword filters.
For a concrete example of why language-level “guardrails” collapse, see the earlier analysis on metaphorical bypass and state restoration in Language Keys and Guardrail Bypass. Shape-shifts beat static heuristics.
The Real Risk Surface
-
Prompt injection isn’t jailbreaks; it’s privilege escalation at the behavior layer. It’s the redefinition of intent itself. The agent still routes, but to goals it never should have accepted. The agent rewrites intent, not just content.
-
Toolformer-style routing composes side effects into plans that no static allowlist anticipates.
-
A single agent running under a host identity can fan out to shells, SaaS APIs, and local tools—without triggering “malicious” signatures—then hand back a perfectly polite answer.
-
Long-lived bindings (PATs, .env exports, shared cloud CLIs) turn every prompt into a potential root path. Most orgs have already leaked at least one of these.
Here’s the anti-pattern I keep seeing:
# developer workstation / build agent
export AWS_PROFILE=prod-admin
export GITHUB_TOKEN=ghp_...
export OPENAI_API_KEY=sk-...
# agent tool
agent.run_tool("deploy", cmd="aws cloudformation deploy --template ...")
No intent separation. No delegation. No provenance. Every step is effectively “do anything the host can do.”
Design Principle: The Agent Never Runs as Itself
The security frame that works:
-
Agentic Identity Binding (AIB): The agent does not have a standing identity. It executes under explicit, step-scoped delegation from a human principal (or upstream service) with constrained authority.
-
Separate intent from execution: Every tool invocation is evaluated by content and context—plan lineage, prompt ancestry, and environment state—not just the final string.
-
Recursive Auth Envelopes (RAE): Temporary permission bubbles tied to the prompt call stack. Each step mints a new envelope with minimal scope, TTL in seconds, and explicit parent linkage.
-
Audit by Chain‑of‑Thought (ACT): Don’t just log “what API was called.” Log the decision chain that led there—redacted, hashed, and structured—so you can answer “why” without storing sensitive thought tokens.
-
Intent‑aware policy engines: Policies should reason over intent classes, tool classes, resource tags, lineage, and risk, not just verb/noun pairs. This is Zero Trust for interpreters.
Where “Managed Control Planes” Fit — And Where They Don’t
Enterprises are building managed control planes to inventory tools, centralize policies, and watch agents. Useful—but monitoring is not control, and planning happens before execution.
Assumptions that don’t hold for real agents:
- Static roles or long‑lived tokens can govern agents
- Tool access can be assigned like microservice permissions
- Policy can be enforced “outside” the agent without lineage
- Human‑in‑the‑loop can be optional except at top levels
- Guardrails can be defined per model or per prompt
What a control plane can do well:
- Catalog tools and capabilities
- Distribute baseline policy bundles and standards
- Centralize observability and debugging telemetry
- Broker credentials from enterprise IdPs
What must live in the intent‑aware runtime (“intent plane”):
- Agentic Identity Binding (who is delegating this step)
- Recursive Auth Envelopes (what scope/TTL/parent lineage applies)
- Lineage‑aware policy evaluation (why this step is allowed)
- Tool Broker preflight and sandboxing (how execution is constrained)
- Audit by Chain‑of‑Thought (how we explain decisions without storing thoughts)
Fast mapping:
- Tool access → Tool Broker + RAE constraints
- Environment scoping → RAE constraints + broker sandbox
- LLM selection/chaining → Intent Gate
- Observability → ACT
- Policy enforcement → Intent‑aware policy over plan lineage
- Credential management → OBO/STS/workload federation at the broker
If you already have a control plane, keep it. Put the Intent Gate + RAE minting + Tool Broker inline on the execution path. That’s where safety actually happens.
Text Diagram: Agentic Runtime With Recursive Auth Envelopes
[ Human Principal ] [ Policy Engine ] [ Tool Broker ] [ Resources ]
| | | |
(OIDC/OAuth2) | | |
|-----(1) Plan -> Intent Extraction ----------------->| |
| |<--(2) Risk, conditions----| |
| | | |
|-----(3) Token Exchange (OBO / STS)----------------->| |
| | | |
| | [ RAE Minting Service ] |
| | | |
| |<--(4) RAE(step_token, scope, ttl, parent_id)--------|
| | | |
| | |----(5) Execute Tool---->|
| | | (scoped creds) |
| | |<----(6) Result ---------|
| | | |
|<------------(7) ACT log: lineage, intent, decision, deltas ------------------->|
Properties:
- Every step gets its own envelope: minimal scope, 60–120s TTL, parent link, prompt hash.
- No envelope, no execution. Envelope used exactly once, bound to tool/resource by claims.
- ACT emits the “why” graph: plan → approvals/holds → envelopes → results.
Reference Implementation: Step‑Scoped Delegation
You can do this today with standards you already use.
1) OAuth 2.0 Token Exchange (RFC 8693) for On-Behalf-Of
Use OBO to mint step tokens that carry envelope claims.
// node/express: RAE minting endpoint
import express from "express";
import jwt from "jsonwebtoken";
import { z } from "zod";
const MintRequest = z.object({
userToken: z.string(), // end-user JWT (id_token or access_token)
parentEnvelopeId: z.string().optional(),
stepId: z.string(),
intentClass: z.string(), // e.g., "deploy.readiness_check"
tool: z.string(), // e.g., "aws.cloudformation.describeStacks"
resources: z.array(z.string()), // ARNs/URLs
maxBudget: z.number().int().optional(), // e.g., API call or $ budget
ttlSeconds: z.number().int().min(10).max(300)
});
const app = express();
app.use(express.json());
app.post("/mint-envelope", async (req, res) => {
const input = MintRequest.parse(req.body);
// 1) Validate user token (OIDC), verify intent against policy engine
const user = await validateUser(input.userToken); // OIDC introspection or local verify
const decision = await policyEvaluate({
subject: user.sub,
intentClass: input.intentClass,
tool: input.tool,
resources: input.resources,
parentEnvelopeId: input.parentEnvelopeId
});
if (!decision.allow) return res.status(403).json({ error: "Denied", reason: decision.reason });
// 2) Mint step-scoped JWT with envelope claims
const now = Math.floor(Date.now() / 1000);
const envelope = {
iss: "https://auth.example.com/rae",
sub: user.sub, // human principal
aud: "tool-broker",
iat: now,
exp: now + input.ttlSeconds,
jti: `rae:${input.stepId}`,
"rae:step_id": input.stepId,
"rae:parent": input.parentEnvelopeId || null,
"rae:intent_class": input.intentClass,
"rae:tool": input.tool,
"rae:resources": input.resources,
"rae:max_budget": input.maxBudget || 0,
"rae:prompt_hash": hashCurrentPrompt(), // stable hash for lineage
"rae:constraints": { network: "egress-allowlist", fs: "readonly" }
};
const token = jwt.sign(envelope, process.env.RAE_SIGNING_KEY!, { algorithm: "RS256", keyid: "k1" });
// 3) Emit ACT event
await actLog({
event: "MINT",
envelopeId: envelope.jti,
subject: user.sub,
decision,
envelope
});
res.json({ token });
});
app.listen(8080);
Bind that token to the Tool Broker. If the token’s rae:tool is aws.cloudformation.describeStacks, any attempt to call s3:PutObject should fail at the broker before it ever reaches AWS.
Key rotation: Sign step tokens with a KMS/HSM-backed key and publish a JWKS with multiple active kids. Rotate the signing key on a 30–90 day cadence; keep the previous public key available until all envelopes it signed have expired. Short TTLs (60–120s) minimize overlap windows and simplify safe rotation.
Cache guidance: Set JWKS cache TTL to 5–15 minutes with jitter; tolerate ±60s clock skew on iat/exp; fail closed only when a refresh attempt succeeds and still lacks a matching kid.
2) AWS STS: AssumeRole With Session Tags From RAE
You can further constrain downstream cloud access. Use the RAE to assume a role with session tags, and SCP/ABAC on those tags.
# python: tool broker side, scoping AWS creds per step
import boto3
import os
def assume_step_role(rae_claims: dict):
sts = boto3.client("sts")
response = sts.assume_role(
RoleArn=os.environ["STEP_EXECUTION_ROLE_ARN"], # limited role
RoleSessionName=f"rae-{rae_claims['rae:step_id']}",
DurationSeconds=min(rae_claims['exp'] - rae_claims['iat'], 900),
Tags=[
{"Key": "rae-step-id", "Value": rae_claims["rae:step_id"]},
{"Key": "rae-intent", "Value": rae_claims["rae:intent_class"]},
{"Key": "rae-tool", "Value": rae_claims["rae:tool"]},
]
)
return response["Credentials"]
Then write IAM policies that only allow actions when tags match envelope claims and resource tags align. This is how you make “minimal, temporary, contextual” real.
Docs:
https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_temp_enable-regions.htmlhttps://docs.aws.amazon.com/IAM/latest/UserGuide/tutorial_attribute-based-access-control.html- OPA:
https://www.openpolicyagent.org/docs/latest/ - Cedar:
https://www.cedarpolicy.com/en
3) Microsoft Entra OBO and Workload Identity Federation
If you live in Azure, the pattern is the same: Entra OBO for step-scoped tokens, and workload identity federation for brokers so you don’t store secrets in .env.
Docs:
https://learn.microsoft.com/azure/active-directory/develop/v2-oauth2-on-behalf-of-flowhttps://learn.microsoft.com/entra/workload-id/workload-identity-federation-overview
4) Okta OIDC/OAuth 2
You can implement token exchange and OBO patterns with Okta’s OIDC server and custom authorization servers.
Docs:
https://developer.okta.com/docs/guides/implement-oauth-for-okta/overview/
5) Standard References
- NIST SP 800-63:
https://pages.nist.gov/800-63-3/ - NIST 800-207 Zero Trust:
https://csrc.nist.gov/pubs/sp/800/207/final - OAuth 2.0 Token Exchange (RFC 8693):
https://www.rfc-editor.org/rfc/rfc8693.html
Intent-Aware Policy: Evaluate Context, Not Just Commands
Treat the LLM like a compiler building an execution tree. Authorize each node against policy with features from the tree: intent, inputs, lineage, environment, and risk.
Example (OPA/Rego) to gate high‑risk intents and enforce envelope-tool alignment:
package agent.policy
default allow := false
# Risk map
risk_score[intent] := score if {
some intent, score
intent_scores := {
"deploy.create_stack": 90,
"deploy.readiness_check": 20,
"data.export_pii": 95,
"code.search_repo": 15,
}
score := intent_scores[intent]
}
allow {
input.subject.loa >= 2 # NIST 800-63 AAL2+
risk_score[input.intent.class] <= 30 # only low-risk auto-approve
input.envelope.tool == input.plan.tool # tool must match envelope claim
every i in input.plan.resources { i in input.envelope.resources } # subset
time.now_ns() < input.envelope.exp * 1000000000
}
# Require approval or break-glass for higher risk
hold_for_approval[msg] {
risk_score[input.intent.class] > 30
msg := sprintf("Hold: intent=%s risk=%d", [input.intent.class, risk_score[input.intent.class]])
}
You can swap OPA for Cedar/AWS if that’s your stack—the key is the feature set, not the engine.
Audit by Chain‑of‑Thought (ACT)
You need to explain “why,” not just “what.” Don’t store raw chain‑of‑thought. Store a structured, redacted, hash-linked graph.
{
"act_version": "1.0",
"session_id": "sess_01H...",
"root_prompt_hash": "sha256:7c9...",
"steps": [
{
"step_id": "s1",
"parent": null,
"intent_class": "deploy.readiness_check",
"prompt_fingerprint": "sha256:12a...",
"features": {
"risk": 20,
"confidence": 0.84,
"reason_codes": ["heuristic.plan.sanity", "past_success.pattern"]
},
"decision": { "allow": true, "policy_id": "opa:v3" },
"envelope_id": "rae:s1",
"tool": "aws.cloudformation.describeStacks",
"resources": ["arn:aws:cloudformation:...:stack/myapp-*"] ,
"result_summary": { "ok": true, "deltas": 0 }
}
],
"hash_chain": [
{ "node": "s1", "hash": "sha256:ab3..." }
]
}
- “reason_codes” are curated, not free‑text.
- “prompt_fingerprint” is a salted hash of redacted prompt sections.
- “hash_chain” lets you verify tamper evidence without storing sensitive tokens.
Runtime Architecture: Treat the LLM as a Recursive Interpreter
Local frameworks and IDE agents need a new runtime shape:
- Prompt Builder: Constructs prompts deterministically with provenance sections (caller, context sources, tool catalogs).
- Intent Gate: Extracts candidate intent(s) with confidence and features (e.g., requires_network=true).
- Policy Engine: Decides allow/hold/deny with human‑in‑the‑loop on thresholds.
- RAE Minting Service: Issues step envelopes bound to tool/resource/TTL.
- Tool Broker: Executes with ephemeral creds; enforces envelope constraints preflight; guards egress and filesystem.
- ACT Logger: Streams lineage/decisions/results; redacts and hashes thought‑adjacent metadata.
A minimal broker preflight:
def preflight_and_run(step_token: str, tool: str, args: dict):
claims = verify_and_decode(step_token)
assert claims["aud"] == "tool-broker"
assert tool == claims["rae:tool"]
assert within_ttl(claims["iat"], claims["exp"])
assert resources_subset(args.get("resources", []), claims["rae:resources"])
creds = scope_runtime_creds(claims) # STS / OBO / workload federation
sandbox = build_sandbox(constraints=claims["rae:constraints"])
with sandbox as iso:
return iso.run(tool, args, creds=creds)
Minimal prompt skeleton (deterministic provenance sections):
[caller]
user_id={sub}
session_id={session}
[context_sources]
files={file_list}
db_refs={refs}
[tool_catalog]
allowed_tools={tools}
[plan]
goal={goal}
constraints={constraints}
[safety]
must_not={risk_conditions}
Handling Prompt Injection as Behavioral Escalation
Yes, you still sanitize inputs. But you also gate plan revisions.
- If the agent modifies its own plan in response to external content, that’s a new intent boundary. Send it back through the Intent Gate.
- If a tool’s output contains executable instructions that shift scope (e.g., “now run terraform apply”), require a new RAE with higher risk class—and likely a human approval.
This is where static guardrails lose. The right answer is stateful adjudication over lineage.
Failure Modes to Design For
- Envelope leak: Short TTL, one‑time use, audience binding, tool binding.
- Broker compromise: No standing secrets; workload identity federation for the broker; rotate signing keys; force mTLS for all hops.
- Time-of-check/time-of-use: Preflight again at execution and check deltas (resource set, network egress).
- Human fatigue: Risk thresholds tuned to keep approvals rare and meaningful; batch low‑risk steps; group approvals by intent class.
What You Can Ship This Quarter
- Kill long-lived keys in
.envfor agents. Replace with step-scoped OBO/STS. - Interpose a Tool Broker between the LLM and tools; forbid direct shell/SDK calls.
- Add an Intent Gate with OPA/Cedar; start with 3–5 high‑risk intent classes.
- Emit ACT logs for “why.” You’ll never go back to stringly‑typed audit.
- Bind cloud actions to session tags from envelopes; enforce with ABAC/SCP.
- Lock egress. Your agent should not exfiltrate silently, ever.
Frontiers: Gaps Most Teams Aren’t Addressing (Yet)
Keep this tight; it’s where the next incidents will come from.
- Cryptographic Prompt Lineage (PL-MAC)
- Bind each prompt segment and tool output with a MAC over: parent hash, envelope ID, tool, and timestamp. Reject execution if lineage breaks.
# broker-side lineage tag
import hmac, hashlib
def lineage_mac(parent_hash: str, envelope_id: str, tool: str, ts: int) -> str:
key = load_kms_key("prompt-lineage-kek")
msg = f"{parent_hash}|{envelope_id}|{tool}|{ts}".encode()
return hmac.new(key, msg, hashlib.sha256).hexdigest()
- Effect‑Typed Tools (Idempotent, Read, Mutate, Destroy)
- Give every tool an effect type and compose policy by effect, not verbs. Ban destructive effects unless envelope intent class permits it.
package agent.effects
default allow := false
effect_of[tool] := eff if {
tool_effects := {
"aws.cloudformation.describeStacks": "read",
"aws.s3.putObject": "mutate",
"aws.ec2.terminateInstances": "destroy"
}
eff := tool_effects[tool]
}
allow {
eff := effect_of[input.plan.tool]
eff == "read"
}
allow {
eff := effect_of[input.plan.tool]
eff == "mutate"
input.intent.class in {"deploy.apply_patch", "ops.rotate_secret"}
}
deny[msg] {
effect_of[input.plan.tool] == "destroy"
msg := "Destructive effect requires explicit break-glass"
}
- Semantic Egress Control
- Don’t just firewall domains. Hash outgoing payloads to semantic embeddings and compare against sensitive vector fingerprints (PII, source code, contracts). Deny or hold when cosine similarity crosses thresholds.
- Timeboxed Planning and Recursion Risk
- Risk increases with recursion depth and plan edits per minute. Auto‑hold when depth > N or when plan drift exceeds a diff budget.
- Cosigned Break‑Glass (WebAuthn in the Envelope)
- High‑risk RAEs carry a
rae:cosignclaim with a WebAuthn signature from a human approver; the broker verifies before issuing creds. No cosign, no execution.
Example envelope claim excerpt:
{
"jti": "rae:s42",
"rae:intent_class": "data.export_pii",
"rae:tool": "s3.getObject",
"rae:resources": ["arn:aws:s3:::pii-bucket/*"],
"rae:cosign": {
"approver": "alice@example.com",
"webauthn_sig": "base64url(AssertionSignature)",
"webauthn_cred_id": "base64url(CredentialId)",
"ts": 1725072000
}
}
- Shadow Execution (Dry‑Run First)
- Run plans against a stubbed environment that asserts expected side effects (e.g., number of resources touched); compare deltas. Only then mint a real RAE for live execution.
Closing
IAM, as we’ve practiced it, assumed stable interfaces and static capabilities. Agentic systems are interpreters composing futures on the fly. If you keep labeling them like APIs, you’ll keep losing to the places your policies can’t see.
Bind identity to the human. Bind power to the step. Bind memory to the audit trail. Then let the interpreter do what it does best—under watch, within scope, and with a reason you can defend.
(ref: NIST 800-207 Zero Trust)